
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- float
- While
- 포인터
- ft_server
- list
- phpmyadmin
- 동적할당
- 42서울
- for
- python
- libft
- Double
- 구조체
- 패킹
- vs코드 단축키
- docker
- nginx
- iF
- cout
- 42Seoul
- 42
- jupyter 단축키
- 자료형
- C++
- 42cursus
- C언어
- Class
- 2차원배열
- 함수
- else if
- Today
- Total
Developer
5.(C++) 함수 본문
디폴트인수
#include<iostream>
using namespace std;
int f(int a=3,int b=4,int c=5,int d=6){
return a+b+c+d;
}
int main(){
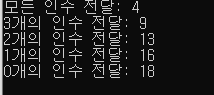
cout<<"모든 인수 전달: "<<f(1,1,1,1)<<endl;
cout<<"3개의 인수 전달: "<<f(1,1,1)<<endl;
cout<<"2개의 인수 전달: "<<f(1,1)<<endl;
cout<<"1개의 인수 전달: "<<f(1)<<endl;
cout<<"0개의 인수 전달: "<<f()<<endl;
return 0;
}
C언어의 함수는 모든 인자를 반드시 작성해 주어야 컴파일 에러가 발생하지 않았다. 하지만 위의 코드처럼 디폴트인수를 사용하면 함수를 호출할 때 생략이 가능하다. 코드1의 함수선언 코드를 살펴보자. 함수의 매개변수를 작성할 때 각 변수에 특정값을 저장하였다. 이 값들은 해당 인수가 전달되지 않았을 때 해당 매개변수에 대입되는 기본값(default)이 된다.
f(1,1,1,1) 은 a,b,c,d에 각각 1을 전달하였다. 따라서 4가 리턴된다.
f(1,1,1)은 a,b,c에 각각 1을 전달하고 d는 전달하지 않아서 d의값은 6이된다. 따라서 9(1+1+1+6)를 리턴한다.
f(1,1)은 a,b에 각각 1을 전달하고 c,d는 전달하지 않았으므로 c는 5 d는 6이된다.
따라서 13(1+1+5+6)을 리턴한다.
디폴트 인수를 사용할 때 주의할 점은 함수호출 시 전달되는 인수는 매개변수의 맨앞에서 부터 전달되므로 중간값이나, 처음값만 생략할 수는 없다는 것이다.
인라인(inline) 함수
함수를 호출하면 스택 프레임이 생성되고, 함수가 종료될 때 스택 프레임이 해제된다. 간단한 함수라도 무조건 함수는 위의 과정을 거치게된다. 만약 불필요한 반복을 줄이기 위해 간단한 코드를 함수로 작성하였다고 생각해보자.
#include<iostream>
#include<cmath>
using namespace std;
double calc(int a){
return sqrt(3)/4*a*a;
}
int main(){
cout<<calc(3)<<endl;
cout<<calc(5)<<endl;
cout<<calc(6)<<endl;
return 0;
}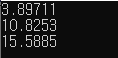
위의 코드의 calc함수는 정삼각형 변의 길이를 받아 넓이를 리턴해주는 함수이다. calc(3)은 sqrt(3)/4*3*3과 같고, calc(5)는 sqrt(3)/4*5*5와 같다는걸 알 수 있다. 분명 반복을 줄이고 쉽게 코드를 작성할 수 있었지만 실제 동작을 살펴보면 매우 비효율적인 것을 알 수 있다. calc가 한 번 호출될 때마다 분기가 일어나기 때문이다(sqrt()는 무시하겠음). 이러한 경우 아래의 코드처럼 작성하는것이 실행 속도가 빠르다.
#include<iostream>
#include<cmath>
using namespace std;
int main(){
cout<<sqrt(3)/4*3*3<<endl;
cout<<sqrt(3)/4*5*5<<endl;
cout<<sqrt(3)/4*6*6<<endl;
return 0;
}하지만 이러한 경우 코드를 작성할 때 매우 귀찮아진다. 인라인 함수는 이러한 고민을 해결해준다.
#include<iostream>
#include<cmath>
using namespace std;
inline double calc(int a){
return sqrt(3)/4*a*a;
}
int main(){
cout<<calc(3)<<endl;
cout<<calc(5)<<endl;
cout<<calc(6)<<endl;
return 0;
}인라인함수는 단순히 함수의 앞에 inline키워드를 작성해 주면된다. 인라인으로 지정된 함수는 함수가 호출되는 곳의 코드에 함수의 본체를 끼워 넣는다. 즉 코드 3과같이 변하게 되는것이다. 이 경우 함수로 분기하지 않아서 실행 속도의 향상을 기대할 수 있지만 각 함수 호출마다 함수의 본체가 삽입되어 실행 파일의 크기는 커지게된다.
하지만 inline키워드를 작성해주었다고 무조건 함수 본체를 삽입하는 것은 아니다. 컴파일러에게 의사만 밝힐 뿐 결정은 컴파일러가 하기 때문이다. 또 inline키워드를 작성하지 않아도 컴파일러가 자동으로 인라인함수로 취급하는 경우도 있다.
중복함수(overloaded function)
#include<iostream>
using namespace std;
int add(int a,int b){
return a+b;
}
double add(double a, double b){
return a+b;
}
int main(){
cout<<add(3,4)<<endl;
cout<<add(3.3,4.2)<<endl;
return 0;
}
C++에서는 같은 이름의 함수를 여러 개 정의할 수 있다. 만약 C에서 실수형 덧셈 함수와 정수형 덧셈함수를 만드려면 각각 다른 이름의 함수를 정의해야한다.
중복함수를 사용할 때 주의할 점은 매개변수의 갯수, 자료형, 순서가 달라야한다는 점이다. 만약 함수의 반환 자료형만 다르다면 중복함수를 사용할 수 없다.
int add(int a,int b)
double add(int a,int b)위의 코드는 컴파일 에러가 발생한다.
또 한가지 주의할 점은 정확하게 일치하는 자료형이 없다면 산술 변환하여 적당한 함수를 선택해 준다는 것이다. 그리고 변환 후에도 하나의 함수를 선택할 수 없다면 에러처리된다.
cout<<add(3,4.4)<<endl;
코드5에서 위의 코드를 추가하면 컴파일 에러가 발생한다. 4.4를 정수로 바꾸어 (int,int)함수를 호출할수도 있고, 3을 3.0으로 바꾸어 (double,double)함수를 호출할 수 도 있기 때문이다.
#include<iostream>
using namespace std;
int add(int a,int b){
return a+b;
}
double add(double a, double b){
return a+b;
}
int main(){
float a=3.1,b=4.2;
short c=3,d=4;
cout<<add(a,b)<<endl;
cout<<add(c,d)<<endl;
return 0;
}
하지만 이렇게 short와 float형으로 선언한 변수를 전달할 경우 short는 int로 float는 double로 명확하게 함수를 선택할 수 있어 정상적으로 작동한다. 그 외에도 중복함수가 불가능한 경우는 아래와 같다.
int add(int a,int b)
int add(int &a,int &b)
//호출부가 같아 불가능
int add(int a,int b)
int add(int a,int b,int c=0)
//이 경우 add(3,4)가 add(3,4)인지 add(3,4,0)인지 애매해 불가능
int add(int a,int b)
int add(int c,int d)
//매개변수의 이름은 다르지만 결국 같은 모양의 함수여서 불가능
'Programming Language > C++' 카테고리의 다른 글
| 7.(C++) 클래스 (1) (0) | 2020.08.01 |
|---|---|
| 6.(C++) 구조체 (0) | 2020.08.01 |
| 4.(C++) 레퍼런스 (Reference) (0) | 2020.08.01 |
| 3.(C++) 제어문 (0) | 2020.08.01 |
| 2.(C++) 입출력 및 자료형 (0) | 2020.08.01 |



